
Hi!
Before 2012, creating analytical queries (that usually scan many rows and have lots of aggregations) from big OLTP databases to feed real-time based reports used in decision making processes, could be quite challenging. Then ColumnStore Indexes arrived and they’ve been enhanced overtime, offering amazing gains both in performance and storage.
Unfortunately, regarding pure OLTP databases, there are many situations in which ColumnStore Indexes can’t (or won’t) be used. There are some great performance enhancements present in columnstore that’s for sure and today I’m going to speak about one that became automatically available since SQL Server 2019 for “traditional” RowStore tables. It’s called “Batch Mode on Rowstore” and it can really boost some of our analytical queries over the “traditional tables” without any effort from our side!
Are you curious about this? Then read on 🙂
Batch mode execution is a query processing method that is used to process multiple rows together, which in large tables where many rows have to be scanned and aggregated, can typically result in queries two to four times faster. But, for some types of aggregations the resulting execution plan will be completely different (from the one used for rowstore mode), much more efficient and that can result in a bigger boost, as I’ll show in one of my demos here, where it gets eight times faster 🙂
Batch mode was introduced with columnstore indexes and until SQL Server 2019 it wasn’t available for RowStore tables. This is one of the enhancements that came with 2019 and the only thing you need to do is set the compatibility level of your database to 150 (or higher).
Bear in mind that this feature will only kick in if the Query Optimizer decides that it will benefit the query execution, which is more likely to happen for queries that perform large scans and aggregations. Although enabled by default, “batch mode on rowstore” can be disabled (and re-enabled) at the database level by means of this database scoped configuration:
--Disabling: ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = OFF --Enabling: ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = ON --Get the current state: SELECT * FROM sys.database_scoped_configurations WHERE name = 'BATCH_MODE_ON_ROWSTORE'
It can also be disabled at the query level, using a query hint that I’ll show in one of the demos below.
Time for some demos, I’ll start by showing a query over a table with aprox. 15 million rows that performs 5 COUNT aggregations:
SELECT COUNT(ID) as count_ID ,COUNT(location) as count_location ,COUNT(PostalCode) as count_PostalCode ,COUNT(AreaCode) as count_AreaCode ,COUNT(NumInhabitants) as count_NumInhabitants FROM LocationsBig

It took one second to complete execution, now let’s have a look at the execution plan and check the execution mode:

“Batch mode execution” was used, this information can be found in the properties of the SELECT operator “BatchModeOnRowStoreUsed=True” and on the other operators such as Table Scan “ActualExecutionMode=Batch” as shown in the image above.
Now as I said, using a query hint, this feature can also be disabled for one particular query while keeping enabled for all the others within the database, like this:
SELECT
COUNT(ID) as count_ID
,COUNT(location) as count_location
,COUNT(PostalCode) as count_PostalCode
,COUNT(AreaCode) as count_AreaCode
,COUNT(NumInhabitants) as count_NumInhabitants
FROM LocationsBig
OPTION(USE HINT('DISALLOW_BATCH_MODE')) --This query hint will disable batch mode on rowstore for this query only

We can see that the query took two seconds to complete (twice the value taken when using batch mode) and we can confirm that “Row mode execution” was used here:

Looking at both execution plans, apart from the different execution mode, they look quite similar, still, having the ability to work on a batch of rows instead of one row at a time (plus using algorithms that are optimized for multi-core CPUs) allowed the execution to be two times faster.
Executing the query from another database using three-part name:
“Batch mode on rowstore” is a database scoped configuration and as such, when executing a query from another database using three-part name, the Query Optimizer will use the scoped configurations defined on the origin database, not the destination one and this may have a significant impact in your queries. So, if you’re executing the query from another database using three-part name and the database in the origin does not have CL >= 150 then “Batch mode execution” will not be used. For example, if I execute my query from a database called [Old_DB] with CL=140, against the [DataSaturdayDB] using three-part name, then “Batch mode execution” will never be used:


So I’ll need to either elevate CL for database [Old_DB] to >= 150 or execute the query directly from the destination database (DataSaturdayDB) to get “Batch mode execution”.
On the other hand, imagine a scenario where the database that holds the tables to be queried, cannot for some reason, have its compatibility level elevated to >= 150, although the database is installed in a SQL Server 2019 (or higher instance). This actually happens frequently in production environments, for example when vendors don’t certificate their products for a higher compatibility level and nobody wants to take the responsibility for that action in SQL Server without having the certification from the product vendor. Well, maybe you can use a workaround to take advantage of the newest features regarding database scoped configurations for a subset of analytical queries (extra product). Yep, try creating a new empty database with CL 150 (or higher) and then run those analytical queries from that database using three-part name.
I’ll show an example, I’m going to create a new database called [DummyDB] with CL = 150 and for the sake of this demo only I’ll lower the CL of [DataSaturdayDB] to 130:
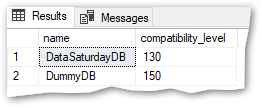
Imagine that [DataSaturdayDB] is one of those databases that were migrated to SQL 2019 but for some reason need to keep the original compatibility level. Damn, I can’t have “Batch mode on rowstore” now… or can I?
I’ll execute the query from [DummyDB] that has CL = 150 and I’ll use three-part name to get to the table in [DataSaturdayDB] and let’s see what happens:
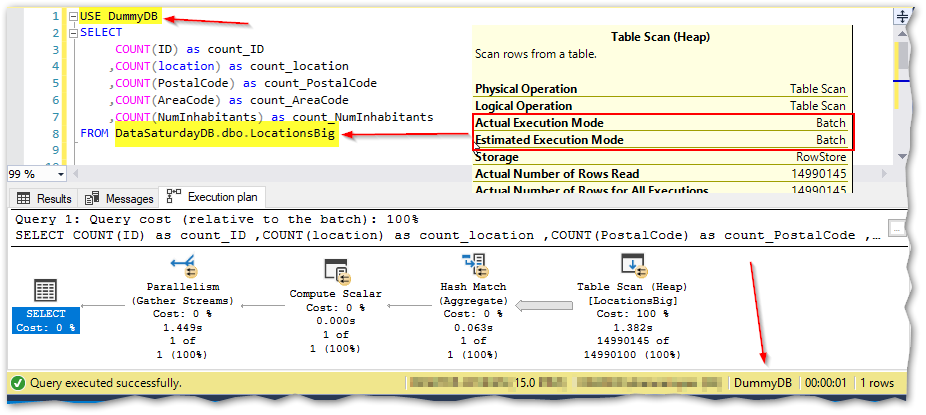
Yes, it worked, I got Batch mode execution for the query!
I know this is far from being an ideal solution and I’m not a fan of it myself but perhaps it can be of use as a workaround for some analytical queries that need to be taken over the database that can’t have its CL elevated for some reason.
The huge boost demo:
OK, in the beginning of this post I spoke about types of aggregations performed on large tables that could hugely benefit from “Batch mode execution” vs “Row mode execution”, let’s see it in action!
The first thing is to make sure that CL is back to 150 in my database (I changed it for the previous demo):
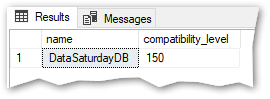
Now, I’ll perform a “small” change in the query that actually has a huge impact behind the scenes and let’s see how it goes. Instead of COUNT I’ll use COUNT DISTINCT and I’ll start by using “Row mode execution” because I’m disabling “Batch mode” in the query:
SELECT
COUNT(DISTINCT ID) as count_ID
,COUNT(DISTINCT location) as count_location
,COUNT(DISTINCT PostalCode) as count_PostalCode
,COUNT(DISTINCT AreaCode) as count_AreaCode
,COUNT(DISTINCT NumInhabitants) as count_NumInhabitants
FROM dbo.LocationsBig
OPTION(USE HINT('DISALLOW_BATCH_MODE')) --This query hint will disable batch mode on rowstore

Yep, having several COUNT(DISTINCT aggregations in a query has always been “painful”!
Now, could it be that “Batch mode execution” produces a different behavior? I’ll execute the same query but this time without disabling batch mode:

Wow! It ran eight times faster, two seconds instead of sixteen! Pretty cool right?
A simple look at both execution plans allows to see immediately the difference that justifies the bigger performance boost (in this case). First I’ll show the execution plan for Row mode execution:

Five independent full streams to gather and aggregate data, one for each COUNT(DISTINCT, Ouch! Yep, this is why having several COUNT(DISTINCT aggregations in a query gets painful and the larger the table and the number of those aggregations the worse it gets!
Now, let’s see the execution plan for the exact same query (with the count distinct) but in Batch Execution mode:

Wow! Only one single stream (instead of 5) to gather and aggregate data for all the aggregations, no wonder it got a lot faster!
This is a good example of how this feature can help boosting some analytical queries over “traditional” rowstore tables but bear in mind that it’s not meant to be a silver bullet. Also remember that this is suited for large scan operations with aggregations and there is no way (that I know of at least) to force its use. Regarding this last consideration, let me illustrate what happens if I execute the same query over a table with the same schema but holding just around 80K rows:


We can see that the Query Optimizer chose “Row mode execution” and there is no way to force otherwise. The point of this last demo is exactly to show that this is a situation that can happen often. Does this mean that the feature is disabled at the database level or that the database compatibility level is less than 150 (SQL 2019)? Well, that could be a possibility (in some cases) that we should also check out but in this case, it’s enabled and CL is 150, the thing is that the Query Optimizer didn’t think that this query would benefit from batch mode execution because the table isn’t big enough.
That’s it for today, hope you can find it useful, Cheers!
