
Hi!
Let me start this post with a question, “Do you think that it can be beneficial to have a single column index for the foreign key column in the child table?“
Well, I believe I can ear three types of answers to this question:
- Always!
- Never!
- It Depends…
Hmm, I guess we’ll have to find out which of these answers is the most appropriate and more importantly: why!
For the folks that answered “Never!” I can think of a couple of reasons, like:
- Join Elimination will still occur, regardless having an index in the column (for the child table) or not;
- Foreign key columns are often used in JOIN predicates in SELECT clauses, but having an index on the foreign key column(s) (alone) by itself will not bring benefits, because the index will not be used and table/index scans will still be made.
Both points presented above are true as I’m about to demonstrate, starting by the Join Elimination feature. In this demo I’ll use two tables called “SalesOrderHeader” (parent table) and “SalesOrderDetail” (child table) having a relationship by means of a Foreign Key (column “SalesOrderID”), like this:

As we can see in the image above, the Foreign Key is both enabled and trusted, this is mandatory for Join Elimination to take place, without it, it will never occur.
There is no Index in column”SalesOrderID” for the “SalesOrderDetail” table, in fact, the only index is on its primary key column:

And now Ladies and Gentlemen, time for the demo where Join Elimination will happen 🙂
I’ll use a query, joining both tables but this query in particular wouldn’t actually need to access the parent table, so thanks to the enforcement of referential integrity by means of the Foreign Key (and since it is both enabled and trusted) SQL Server will be smart enough to ignore the parent table, hence only accessing the child table that is the one that is necessary in this case:
SELECT child.* FROM SalesOrderDetail as child INNER JOIN SalesOrderHeader as parent ON child.SalesOrderID = parent.SalesOrderID WHERE child.UnitPrice BETWEEN 50 AND 70
The truth is that the above query is badly written, since it is a INNER join and by not using any column from the parent table (apart from the join predicate) the previous query should have been written like this:
SELECT * --Don't use * in real queries please 🙂 FROM SalesOrderDetail WHERE UnitPrice BETWEEN 50 AND 70
Yep, that is the way it should have been written, not involving the “SalesOrderHeader” table at all! Unfortunately there are many cases where queries are poorly written, some times it also happens due to Copy/Paste operations used by developers to save time when writing similar queries and the final result when running those queries can be real bad. But this particular story will have a happy ending, since SQL Server is going to be smart and ignore the parent table and this is Join Elimination working for us:
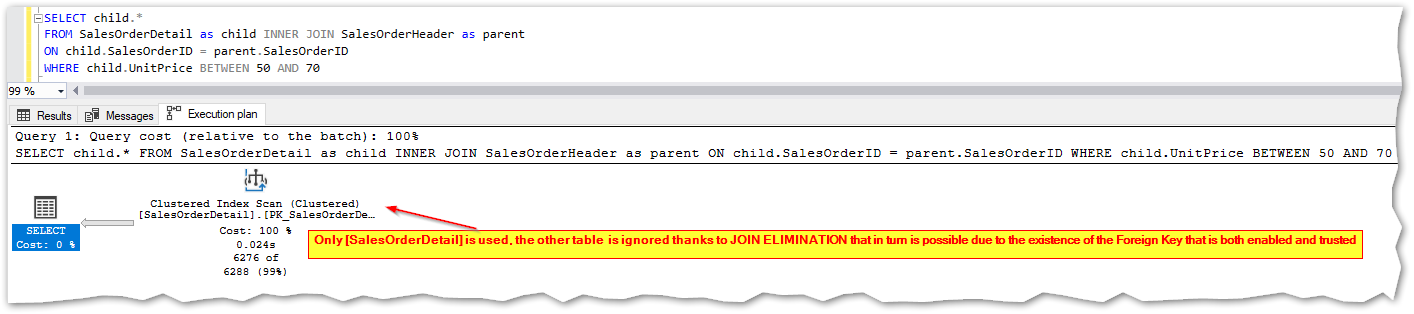
So this proves that Join Elimination works fine without the need for an index in the F.K. column!
Before I go to the next point however, I must share with you a situation that happened to me at work some time ago, where Join Elimination wasn’t “working” although the F.K. was present, enabled, trusted and the query itself was absolutely suited for Join Elimination to kick in! I don’t remember the query anymore but at the time I was puzzled by the situation and after a little thought I found the reason and that’s the most important, so I’ll simulate it here and using the exact same query we saw previously, check this out:

Wow, no way, did I remove the foreign key? is it disabled? is it not trusted anymore? No, regarding the F.K. all is well, the query is exactly the same as above but something is different yes and that’s what’s responsible for this situation.
I’m one of those guys that believe performance tuning starts at the database design level. We should always think over and carefully decide every aspect in database design and one of the aspects that is many times neglected regards column nullability. For each column in all tables in our database does it need to be filled with a value, yes or no? In this particular case, does it make any sense to have a “SalesOrderDetail” that doesn’t have its own “SalesOrderHeader”? Well if not then let’s mark the “SalesOrderID” column for the “SalesOrderDetail” as not nullable. That is how it was for my first demo but not for this one:

Yes, in this case there is the possibility of having null values in the “SalesOrderID” column, so now when using the INNER join, both tables must be scanned, the only way Join Elimination could be used here would be in case of a LEFT Join. I thought this was something worth mentioning, also to highlight once more the importance of the database design phase (as a whole I mean)
Moving on, in my next demo I’ll show that even if I create an Index in the “SalesOrderID” column of the “SalesOrderDetail” table, it won’t be used by the JOIN predicate itself. First, let’s create the index:

Next, execute the query:
SELECT parent.OrderDate, parent.ShipDate, parent.DueDate, parent.SalesOrderNumber, child.OrderQty FROM SalesOrderDetail as child INNER JOIN SalesOrderHeader as parent ON child.SalesOrderID = parent.SalesOrderID WHERE child.UnitPrice BETWEEN 50 AND 70

As I’m sure everyone expected, the newly created index is not used, just because the column is mentioned in the JOIN predicate, it wouldn’t help in anything so it is ignored.
So, this proves that having an index on the foreign key column(s) (alone) by itself will not bring benefits when that column is simply used in the JOIN predicate in SELECT clauses.
Does this mean that I agree with who answered that such indexes should never be created? Not at all, as I also admit that in some scenarios creating them may not make a significant difference… So yes, I prefer the usual “It Depends…” answer 🙂
So far we’ve seen some situations where having an index in the foreign key column of the child table didn’t make a difference, now it’s time to present some situations that can make a huge difference! I’m going to use examples based on real cases that I’ve seen happening several times in some databases/customers.
I’m starting with a very small table, called T1, that only has two columns and one thousand rows:

Now, I’m simply going to delete one row from this table:

The DELETE was instantaneous just as expected. Now I’m going to do the same thing over a table called TB1, that has the same structure and the same number of rows as T1:
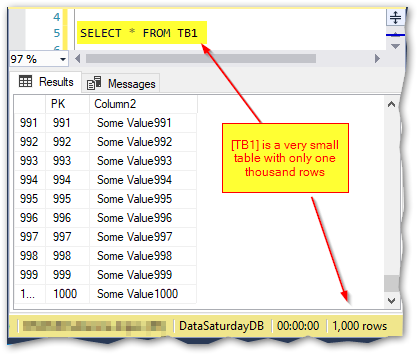
Now I’ll delete one row from the table:

This time however, the DELETE statement took 5 seconds to execute over such a small table! And during this demo nothing else is running, so the delay doesn’t regard blocking or any potential concurrency issues… strange, right? both tables have exactly the same structure and the same number of rows….
Ok, let’s have a look at the execution plans and find out what’s going on:

The “hidden catch”, as we can see in the execution plans above, lies in the fact that all the child tables related with T1 have an Index in the foreign key column, while none of the tables related with TB1 have Indexes in the foreign key column, hence on the first case we have Index Seeks being performed to look for possible matches for value 999 in the corresponding columns (and instantaneous execution of the Delete) whereas on the second case, Index Scans are performed, resulting on a much slower execution.
Important: In this example all the tables involved are very small, but in large child tables, this can result in a much more expressive performance difference, expanding to several minutes!
But this may not end here. In the previous example all the foreign keys were created with “NO ACTION” for the DELETE statement, meaning that if the value to be deleted from the parent table is found on a child table, the delete statement will fail and an error will be raised.
Sometimes however, foreign keys are created with the DELETE CASCADE option. If this was applied to our previous example, then deleting the row for value 999 in the parent table would imply that SQL Server would look for that value in the child tables and when found, the corresponding rows in the child tables would automatically be deleted as well. Could this make a significant difference in terms of performance?
Let’s check it out, first I’ll verify that all the F.K.’s now have DELETE CASCADE action:
SELECT name as fk, OBJECT_NAME(f.parent_object_id) child_table, OBJECT_NAME(f.referenced_object_id) as parent_table,
f.type_desc, f.delete_referential_action_desc, f.update_referential_action_desc, f.is_disabled, f.is_not_trusted,
COL_NAME(f.parent_object_id, k.parent_column_id) as child_column
FROM sys.foreign_keys f INNER JOIN
sys.foreign_key_columns k on (k.constraint_object_id = f.object_id)
WHERE OBJECT_NAME(f.referenced_object_id) IN ('T1', 'TB1')
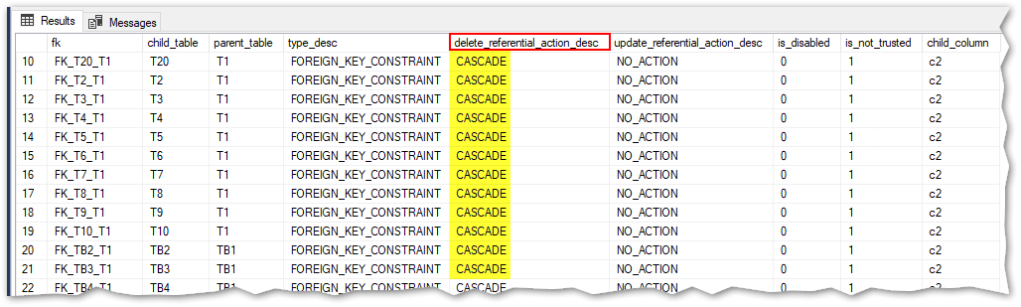
Great, we’re ready for the test, here we go!
Well, both executions took the same time as before:

Does this mean that nothing changed when DELETE CASCADE was activated?
Looking at the execution plan will help answering the question:

From the execution plan above, we can see that now SQL Server looks for the value 999 in every child table in order to delete the corresponding rows, although in this case the value is not present in any of the child tables. For the DELETE in table T1, since all the child tables have an Index in the F.K. column, an Index Seek is performed in each child table but for table TB1 since none of the child tables have an Index in the F.K. column, a Table Scan must be used, taking longer to execute. Ok, got it, Index Seek vs Table Scan but that already happened before applying the CASCADE action, so what has changed? Well, as shown in the above execution plan (“Table Delete” operator), SQL Server will now automatically delete child rows and what does this imply?… Exactly, LOCKS!
If we are on an isolated test environment, it’s likely that while testing our T-SQL statements no one else is using the database but in a real production environment for a OLTP database, especially concerning its core transactional tables, it’s the other way around, I mean there’s a high probability of having several concurrent statements querying the same tables at the very same time. As we know, SQL Server uses Locks as a mechanism to manage and ensure proper transactions isolation. An experienced SQL developer will take this into consideration while writing the statements but I think it’s fair to admit that sometimes “hidden” things like cascading over child tables may go unnoticed and I’m going to highlight this particular situation.
So, going back to our DELETE over table T1, let’s see how many exclusive locks (X) we have while deleting one row with value 999 from the table (regarding only this session @@SPID):
BEGIN TRAN
DELETE T1 WHERE PK = 999
SELECT resource_type, request_mode,
CASE resource_type WHEN 'OBJECT' THEN 'Table --> ' + OBJECT_NAME(resource_associated_entity_id) ELSE CAST(resource_associated_entity_id as varchar(100)) END as Entity,
request_type, request_status
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID
AND request_mode = 'X'

Only one Exclusive Lock, on the T1 table itself on that particular row, sounds great! I know what you’re thinking but remember that the value 999 does not exist in any of the child tables. For example, if there were five rows matching the value 999 on the child table T14, then we would have five more Exclusive Locks (one for each row/key).
Of course there are other locks but less “Exclusive”, let’s see them all:

This allows concurrent transactions to perform a number of actions over the nineteen child tables, while the DELETE is running for the parent table T1. Like this one for example:

Now, let’s try to do the same delete but this time over table TB1. Remember this is the scenario where there are no Indexes over the F.K. column in the child tables:

Wow! An exclusive lock (X) in every child table! This can hugely impact concurrent transactions, assuming these are transactional core tables in your database in the production environment.
Let me try the same UPDATE over one of its child tables now, ups we have a problem:

The UPDATE to table TB14 made in a different session, is blocked by the DELETE made to TB1. Same thing will happen if we try to update any of the nineteen child tables during the time the DELETE lasts for TB14.
Let’s check the lock request status for the UPDATE statement:
SELECT resource_type, request_mode,
CASE resource_type WHEN 'OBJECT' THEN 'Table --> ' + OBJECT_NAME(resource_associated_entity_id) ELSE CAST(resource_associated_entity_id as varchar(100)) END as Entity,
request_type, request_status, request_session_id, r.wait_time
FROM sys.dm_tran_locks t INNER JOIN sys.dm_exec_requests r
ON t.request_session_id = r.session_id
WHERE request_status = 'WAIT'

There it is, waiting for the DELETE to finish. If the delete takes a few minutes and there are hundreds of concurrent transactions using any of the child tables, assuming the respective applications have a command timeout of 30 seconds…. yeah, you can see what happens and it’s not good!
I can’t even make the tiniest SELECT without getting blocked, since the scope of exclusive lock is the entire (child) table:
It’s true that in some cases (like the SELECT above), even not having the Index in the F.K. column of the child table, it’s possible to avoid these blocking issues, using specific Transaction Isolation Levels but this can also have other consequences that we must be aware of. “Transaction Isolation Levels” is a major subject that would give by itself a series of posts, as such, it goes beyond the scope and purpose of this post, nonetheless and not loosing focus, in this case, using the Indexes in the child tables would definitely be the best approach.
Another important thing to point out is that there is a feature in SQL Server known as “Lock Escalation” meaning that at some point, if for example there are many X locks held at row/key level for one table, it can automatically escalate to a single X lock over the entire table. Again, while worth mentioning here for awareness, this is a subject that goes beyond the scope of this post and by the way, there is a myth that the threshold for the escalation to take place is five thousand locks but it’s actually a lot more than that. Perhaps I’ll demonstrate it on a new post dedicated to Lock Escalation in the future 🙂
Conclusion:
In this post I’ve demonstrated that depending on the number, size, relationship type and usage of the tables in OLTP databases it can be extremely beneficial to have indexes on the F.K. columns for the child tables and although I can’t say that it will always be beneficial, as a rule of thumb, I think we should do it. If you find that the Index existence “hurts” in a particular case, you can collect the evidence and then simply remove it.
That’s it for today, hope you can find this helpful, Cheers!

One thought on “The “hidden” benefits of Indexes in Foreign Key columns”