
Hi,
This is the second of three posts dedicated to HADR solutions in Azure SQL Database. In HADR in Azure SQL Database (Part I) I presented the “Scale out read-only Database” feature. In this one, I’ll talk about Active Geo-Replication and in HADR in Azure SQL Database (Part III), I’ll introduce “Auto-failover groups”.
So, first of all, what is Active Geo-Replication?
“Active geo-replication is a feature that lets you create a continuously synchronized readable secondary database for a primary database. The readable secondary database may be in the same Azure region as the primary, or, more commonly, in a different region. This kind of readable secondary database is also known as a geo-secondary or geo-replica.“
Taken from (https://learn.microsoft.com/en-us/azure/azure-sql/database/active-geo-replication-overview?view=azuresql)
Using Active Geo-Replication it is possible to have a readable replica in any tier (even Basic) and as stated above, the readable secondary database may be in the same Azure region as the primary, or in a different region. I’ll now demonstrate how to create and use it.
Unlike the “Scale out read-only Database” feature, Active Geo-replication has the advantage of being usable in every service tier, even the lowest one, so in my demo I’ll use the Basic tier.
Using the Azure Portal (there are other ways to do it), I’ll go to my AdventureWorks Database that lies in the “Basic” service tier. In order to create a read-only replica in another region, I’ll simply click in “Replicas” below “Data management” on the left panel:

From the “Replicas” panel we can create one or more replicas for our database:
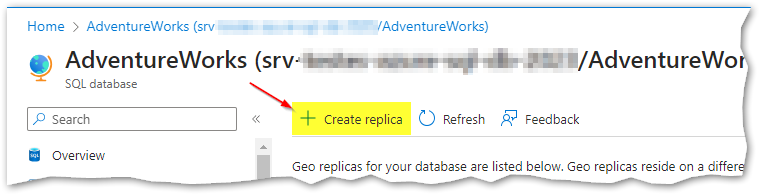
Actually there is a number of ways this can be done, one of them is by using the Azure Portal as shown in the image above. The process is very user friendly and pretty much straightforward. But since I’m such a fan of T-SQL, I can’t resist showing how to add a secondary readable replica using this language:
--Creates a geo-replication secondary database with the same name on a partner server, --making the local database into a geo-replication primary, and begins asynchronously replicating data from the primary to the new secondary --This command is executed on the master database on the server hosting the local database that becomes the primary. ALTER DATABASE AdventureWorks ADD SECONDARY ON SERVER [my-failover-server] WITH ( ALLOW_CONNECTIONS = ALL )
Once created, the geo-secondary replica is populated with the data of the primary database. This process is known as seeding. I’ll show one way to follow this process right after the creation of the read-only replica:
SELECT db.name as primary_database, grl.start_date, grl.modify_date, grl.partner_server, grl.partner_database, grl.replication_state_desc, grl.role_desc, grl.secondary_allow_connections_desc, grl.percent_copied FROM sys.geo_replication_links grl INNER JOIN sys.databases db ON grl.database_id = db.database_id
Immediately after the creation, the seeding starts:

After the seeding takes place, we can see that all database is copied and the replication state changes:

Let me show you how it looks in the Azure Portal (and yes there several other ways but in this post I’ll stick with Azure Portal and T-SQL in my demos :-))

Good, we now have a (asynchronous) secondary replica and read-only workloads can be directed to it. Also in this case, by being in a different region there is extra protection in a DR scenario.
Out of curiosity, just a few months ago, the “planned failover” wasn’t available for Active Geo-Replication, it’s nice to notice that it’s already implemented! Yep, things are always evolving in Azure, which is great!
Oh, I know what you’re thinking at this point: having a replica in a different region is good for DR purposes but due to potential latency issues it can be sub-optimal for HA and/or some heavier read-only workloads… Right, well the good news are that Active Geo-Replication allows more than one secondary replica, so why don’t I add one in the same region as the primary and another in a different region, thus having a even better HADR solution? (bear in mind that having multiple databases will increase costs in Azure, but in some scenarios this may be a great solution)
So, let me show you the final solution for this Demo:
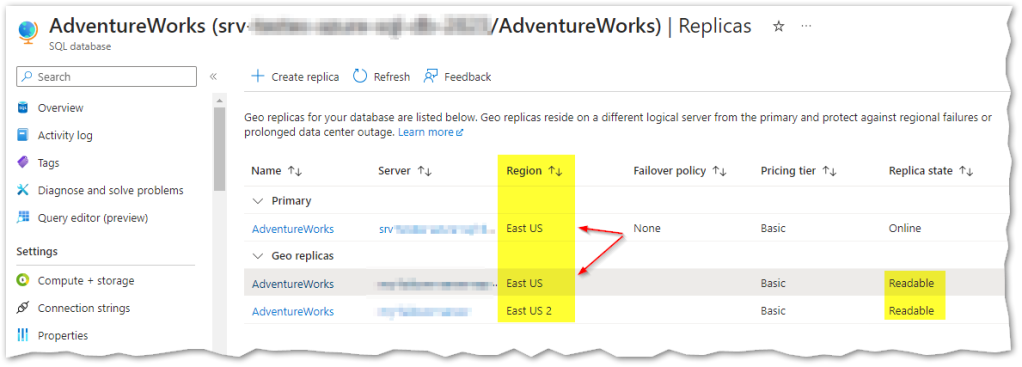
Awesome!
Now we need to see this working, so I’ll connect to the primary server and one of the readable replicas and make some queries:

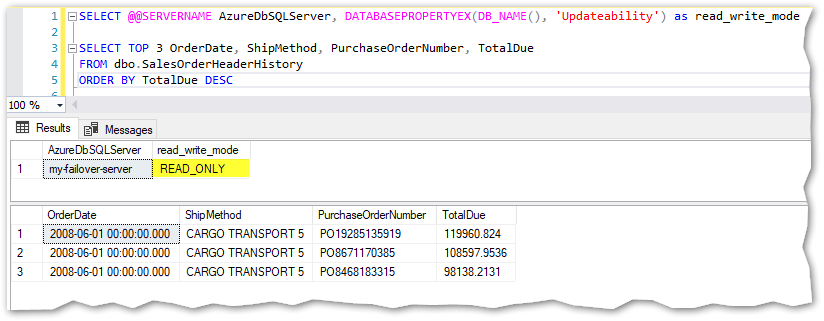
Again I can use function DATABASEPROPERTYEX(DB_NAME(), ‘Updateability’) to know if I’m connected to the primary or a read-only replica:

As mentioned in the image above, only the primary is read-write. Using the next query, I’ll create a new table to keep historic data regarding SalesOrderHeading and since it implies the creation of a new table plus inserting data into it, the statement will only work on the primary server, not in the read-only replica as shown below:
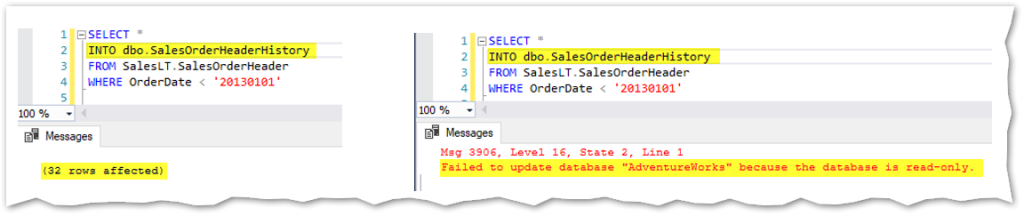
But all the changes made in the primary are automatically propagated to all the secondary replicas, asynchronously. For example, I can now read data regarding the newly created table in any of the read-only replicas:
Last but not least, Active Geo-Replication allows to failover single databases between servers in case of need. Both Planned Failover (without data loss) and Forced Failover (with potential data loss) are supported now. Forced Failover could be used for example in case of a disaster due to a severe failure on the primary server, whereas Planned Failover usually occurs for operational reasons (Architecture requirements, performance boosting, security guidelines, testing, etc.). In the picture above I’ve shown that failovers can easily be performed using the Azure Portal. From the “Replicas” panel, choose the replica that should become the new primary and then click the “three dots” button on the right side. A context menu will appear allowing to failover (either planned or forced) or stop the replication:
I’ll also show how to do a failover for a single database (in this case AdventureWorks) using T-SQL. First, as when using the portal, we must choose the current read-only replica that should become the new primary and connect to it. Bear in mind that the failover statements below must always run from the master database.
For a Planned Failover (without data loss):
ALTER DATABASE AdventureWorks FAILOVER
For a Forced Failover (with potential data loss):
ALTER DATABASE AdventureWorks FORCE_FAILOVER_ALLOW_DATA_LOSS
After I executed the planned failover, the chosen read-only replica became primary and vice-versa:

So far so good and so simple, right? But I have a question, now what happens to all the applications that were connecting to the primary and to the read-only replicas previously?…
Well, this leads me to disclose one potential drawback when using Active Geo-Replication: There are no listeners here and no way to automatically perform the routing for connections to the primary or secondary replicas, at least for the moment. This means that after a failover, applications may fail if the respective connection strings aren’t properly changed manually, i.e. read-write connections must aim the new primary as the Data Source or else they’ll stop working properly. It is also possible to have code inside the application that starts by checking the replicas roles and then internally uses the connections accordingly but that requires implementation by the dev team, it’s not automatic.
So remember that after a failover, the connection strings for the applications must be updated in order to continue working properly.
If this “limitation” is kind of a showstopper for you, don’t loose hope, you can try using “Auto-failover groups” to overcome it. I’ll cover this feature in my third and last post dedicated to HADR in Azure SQL Database.
Hope you could find this useful, Cheers!
